2. 디지털 데이터의 표현
1) 데이터의 구성단위
> 물리적 단위
- 실제 물리적 장치(메모리, 저장장치)에서 사용되는 단위로 0, 1의 내용만 저장할 수 있으며 최소 단위는 bit
| 단위 |
크기 |
| 비트(bit) | 0이나 1만 저장하는 최소 단위 |
| 쿼터(quarter) | 2bit = 1/4 byte |
| 니블(nibble) | 4bit = 1/2 byte |
| 바이트(byte) | 8bit |
| 워드(word) | 16bit = 2 byte |
| 더블 워드 (double word) | 32bit = 4 byte |
| 쿼드 워드 (quard word) | 64bit = 8byte |
> 논리적 단위
- 정보를 저장 및 처리하는데 사용되며, 디지털 포렌식 관점에서 분석 대상이 되는 최소단위
| 단위 |
크기 |
| 필드(field) | 여러개의 바이트, 워드가 모여 이뤄진 파일 구성의 최소단위 |
| 레코드(record) | 프로그램 내의 자료 처리 기본 단위 (논리적 레코드) |
| 블록(block) | 저장매체에 입출력될 때 기본 단위 (물리적 레코드) |
| 파일(file) | 관련된 레코드의 집합으로 하나의 프로그램 처리 단위 |
| 데이터베이스(database) | 파일(레코드)의 집합, 계층적 구조를 갖는 자료 단위 |
2) 수체계 (Number system)
디지털 데이터는 기본적으로 이진수를 사용
1. 2진수 (Binary Numbers)
- 컴퓨터 메모리의 기본 단위인 1byte(8bit)에 저장된 데이터를 나타냄
2. Byte 계산
- 00000000 00000000 ~ 11111111 11111111 의 값을 저장할 수 있으며 0 ~ 65535 의 수를 저장할 수 있다.
3. 리틀 엔디안 ( Littele Endian)
- 리틀 엔디안은 오른쪽부터 왼쪽으로 저장되는 방식

> 리틀 엔디안 사용 시스템
- 인텔 프로세서, DEC의 알파 프로세서
- 리틀 엔디안 방식으로 저장된 숫자는 최소 바이트가 원래 있던 자리에 그대로 머물 수 있으며, 새로운 자리 수는 최대 수가 있는 주소의 오른쪽에 추가되어 컴츄터 연산이 매우 단순해시고 빠르게 수행 가능
Ex) 1111 + 0001 = 10000
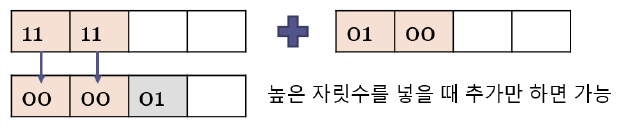
4. 빅 엔디안 (Big Endian)
- 빅 엔디안은 왼쪽부터 오른쪽으로 저장되는 방식

> 빅 엔디안을 사용하는 시스템
- IBM 370 컴퓨터, RISC(Reduced instruction Set Computer), 모토로라 마이크로 프로세서
- 일련의 문자나 숫자 저장에 잇어 자연스서운 방식
- 숫자의 경우 두 숫자를 더한 결과를 저장하기 위해 모든 자릿수를 오른쪽으로 옮겨야 하는 일 발생
Ex) 1111 + 0001 = 10000

7. 16진수 (Hexadecimal Numbers)
- 디지털 데이터는 2진수를 사용하지만 모든 데이터를 2진수로 표현하면 화면에 출력 또는 처리할 때 비효율적
- 니블(4bit) 단위로 묶어서 표현하는 16진수를 사용하는 것이 이용에 편리함

8. 고정소수점
- 고정 소수점 연산은 정수 데이터의 표현과 연산에 사용하는 방식이다.
- 첫 번째 비트는 부호 비트로 양수(+)는 0, 음수(-)는 1로 표시
- 나머지는 정수부가 저장되고, 소수점은 맨 오른쪽에 잇는 것으로 가정

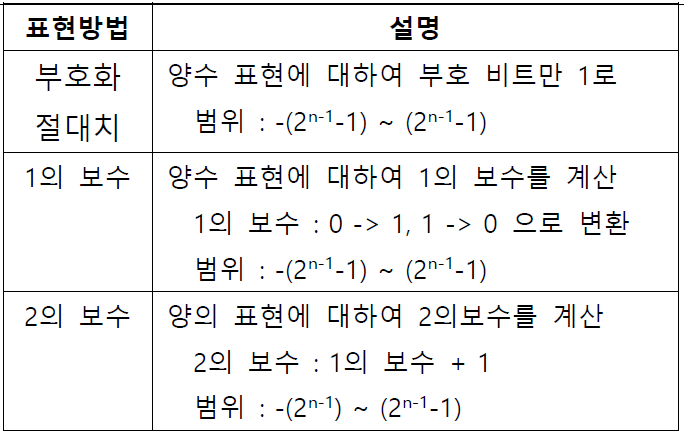
- 부호화 절대치 , 1의 보수는 표현 범위 -127 ~ 127
- 2의 보수 표현 범위 -128 ~ 128
9. 부동 소수점
- 실수 데이터의 표현과 연산에 사용
- 실수 표현시 소수점의 위치를 고정하지 않고 그 위치를 난타내는 수를 따로 적는 것으로, 유효숫자를 나타내는 가수와 소수점의 우치를 알 수 있는 지수로 표현

3) 문자
1. 문자 코드
- 디지털 포렌식 분석에서 문자 데이터를 분석할 때, 문자코드에 대한 이해가 있어야 의미를 보다 정확히 파악 가능
- 특정 2진값으로 한글, 영러, 숫자, 특수문자 등의 모양을 정해놓은 문자 코드를 사용하고, 이는 세계표준으로 지정하여 서로 다른 시스템에서도 동일하게 해석될 수 있어야 한다.
2. ASCII 문자 코드
- 미국 표준협회(ANSI)가 제정한 자료 처리 및 통신 시스템 상호간의 정보 교환용 표준 코드.
- 제어부호 33자, 그래픽 기호 33자, 숫자 10, 알파벳 대소문자 52자, 공백문자 1개로 구성
- 영문을 표기하는 대부분에 시스템에서 사용
= 7비트, 128가지 기호를 정의하여 1바이트로 하나의 문자를 표현
3. BCD코드 (Binary Coded Decimal, 2진화 10진 코드)
- 10진수 1자리의 수를 2진수 4bit로 표현
- 대표적인 가중치 코드(Weight Code)
- 사용이유 : 10진수 입출력이 간편함
4. EBCDIC (Extended Binaty Coded Decimal Interchange Code, 확장 2진화 10진 코드)
- 하나의 영숫자 코드가 8비트 구성. 총 256개 문자 코드를 구성할 수 있으나, 실제 문자코드는 아스키 코드와 동일한 128bit개 이다.
- 에러검출을 위한 패리티비트 추가시 총 9비트 사용 4개의 zone bit + 4개의 digit bit로 구성
5. 3초과 코드 (Excess-3 code)
- 10진수를 표현하기 위한 부호
- ECD 부호에 3을 더한것과 같다
- 부호를 구성하는 어떤 비트값도 0이 아니다.
- BCD code 중에서 산술 연산 작용에 가장 적합
- 대표적인 자기 보수코드, 비 가중치 코드
6. 그레이 코드 (Gray Code)
- BCD 코드의 인접하는 비트를 XOR 연산하여 만든 고드
- A/D 변환, 입출력장치 등에 주로 사용
- 하드웨어 에러를 최소로 하는데 적합
7. 패리티 검사 코드 (Parity Check Code)
- 코드의 오류를 검사하기 위해서 Data bit이외에 1bit를 추가
- 패리티 비트 : 오류 정보를 검출하기 위해 사용되는 비트
- 1bit만 오류 검출 가능 : Odd parity (홀수 = 기수 패리티)
Even parity (짝수 = 우수 패리티)
8. 해밍코드 (Hamming Code)
- 오류 검출 및 교정이 가능한 코드
- 해밍코드는 2bit의 오휴를 검출할 수 있고, 1bit의 오류를 교정할 수 있다.
※ 코드의 분류
| 분류 | 코드 종류 |
| 가중치 코드류 | BCD(8421) 코드, 2421 코드, Biquinary 코드, 51111 코드 |
| 비가중치 코드 | Excess 3 코드, Gray 코드, 2 out-5 코드 |
| 자기 보수 코드 | Excess 3 코드, 2421 코드, 51111 코드 |
| 오류 검출용 코드 | 해밍코드, 패리티 검사 코드, Biquinary 코드, 2 out-5 코드 |
9. 한글 조합형, 완성형, 확장형 코드
1) 조합형 코드
- 2바이트 완성형 코드가 발표되기 전까지 사용되던 코드로 한글로 초성, 중성, 종성에 따라 조합하여 표현
- 이론 상 한글 11,172자를 모두 표현할 수 있으며, 한글 입력에 대한 처리가 쉬웠으나 Ms Windows95에서 완성형 코드를 선택함에 따라 1990년도 중반까지 사용
2) 완성형 코드
- 2바이트 완성형 코드를 의미하며, EUC-KR로 표준화 되어 사용된다.
- 완성형에서 한글은 연속된 두 개의 바이트를 이용해서 표현할 수 있으며, 첫 번째 바이트와 두 번째 바이트 모두 16진수 사이의 값을 가진다
- 완선형 코드는 한글을 2,350자 지원 Ms Windows에서 선택함에 따라 최근까지 널리 이용됨
3) 확장 완성형 코드
- Ms에서 완성형 코드에 글자를 추가한 것으로 코드페이지 949로 불린다. ECU-KR과 마찬가지로 한글을 표현하는데 2바이트를 사용
10. 유니코드 (Unicode)
- 전 세계의 모든 문자를 컴퓨터에서 일관되게 표현하고 다룰 수 있도록 설계된 산업 표준 코드, ISO 10646으로 정의된 USC를 말함
1) USC-2와 USC-4
- USC-2는 2바이트를 사용하여, 유니코드 31비트 문제 중 16비트 이하의 부분만 표현
- USC-4는 4바이트를 사용하여 31비트의 모든 유니코드 영역에 표현
2) UTF-8
- 가장 일반적으로 사용하는 유니코드 포멧
- 31비트 유니코드 1~6개의 바이트에 나누어 저장
- 첫 번째 바이트에서 몇개의 바이트로 구성된지 파악
- 아스키 코드 영역은 1바이트로 표현
- 한글은 보통 3바이트로 표현
- Ms에서도 UTF-8 지원
3) UTF-16
- USC-2 문자열 안에 유니코드의 21비트 영역의 문자를 표현하기 위해 도입, USC-2의 확장 버전
- 16비즈 위의 21비트까지 표현 가능
4) UTF-32
- 각 문자를 4바이트로 표현
4) 데이터 인코딩
1. 데이터 인코딩
- 숫자, 문자, 시간 등의 데이터를 다양한 인코딩 알고리즘에 따라 특수한 형태의 데이터로 변환
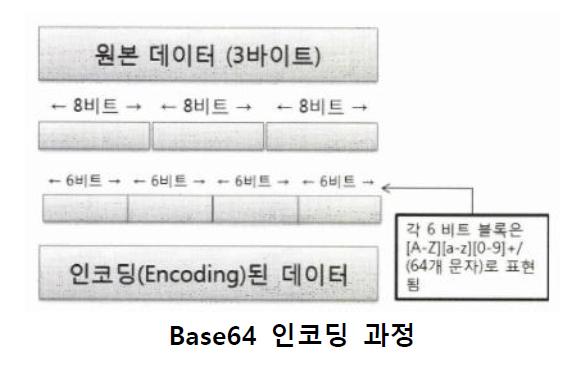
2. Based 64
- 8비트 바이너리 데이터를 ASCII 영역의 문자들로만 이뤄진 일련의 문자열로 변환하는 인코딩 방식
- 임의의 바이너리 데이터를 62개 ASCII문자의 조합으로 표현
- 컴퓨터는 2진수를 사용하므로 62진수로 표현하기 위해서는 6비트의 2진수를 사용
- Based64 인코딩은 E-Main\l을 통한 이진 데이터의 전송등에 많이 사용
3. Based58
- Based58은 Based64와 같이 이진 데이터를 text로 변경해주는 인코딩 기법중 하나
- 형태로 보면 Based64와 비슷하지만 내부 알고리즘은 다르다
- 입력된 값을 big number로 변결하여 58로 나누고 그 나머지를 지정된 table에 대응하는 문자로 치환
- 용도는 사용자가 직접 타이핑하거나 Copy & Paste를 용이하게 하기 위해서 사용된다.
'자격증 > 디지털 포렌식 전문가 2급 필기' 카테고리의 다른 글
| 1과목_컴퓨터 구조와 디지털 저장매체_03 _03 디지털 기기 및 저장 매체 (0) | 2020.04.07 |
|---|---|
| 1과목_컴퓨터 구조와 디지털 저장매체_01 컴퓨터의 구조 (0) | 2020.04.06 |